概念 :
設計 :
實作 :
!pip install -q sentence-transformers chromadb faiss-cpu pandas
# ===== imports =====
import os, json
import numpy as np, pandas as pd
from sentence_transformers import SentenceTransformer
# 嘗試載入 Chroma
try:
import chromadb
from chromadb import PersistentClient
CHROMA_AVAILABLE = True
except Exception:
CHROMA_AVAILABLE = False
# 嘗試載入 faiss
try:
import faiss
FAISS_AVAILABLE = True
except Exception:
FAISS_AVAILABLE = False
if os.path.exists("faqs.csv"):
df = pd.read_csv("faqs.csv", encoding="utf-8-sig")
else:
data = [
{"id":"q1","question":"如何申請退貨?","answer":"請於訂單頁點選退貨申請並上傳商品照片,客服將於 3 個工作天內處理。"},
{"id":"q2","question":"運費如何計算?","answer":"單筆訂單滿 1000 元享免運,未滿則收取 60 元運費。"},
{"id":"q3","question":"可以更改收件地址嗎?","answer":"若訂單尚未出貨,您可在會員中心修改收件地址。"},
{"id":"q4","question":"付款方式有哪些?","answer":"我們支援信用卡、LINE Pay 與貨到付款。"},
{"id":"q5","question":"商品多久可以到貨?","answer":"一般商品 3–5 個工作天內送達,偏遠地區約 7 天。"},
{"id":"q6","question":"如何查詢訂單狀態?","answer":"請至會員中心 → 訂單查詢頁面,即可查看目前狀態。"},
{"id":"q7","question":"發票會如何提供?","answer":"電子發票將寄送至您填寫的 Email,也可於會員中心下載。"},
{"id":"q8","question":"商品有瑕疵怎麼辦?","answer":"請拍照後至客服中心填寫表單,我們將盡快處理換貨或退款。"},
{"id":"q9","question":"有提供客服聯絡方式嗎?","answer":"您可透過線上客服或來電 0800-123-456 與我們聯繫。"},
{"id":"q10","question":"如何使用優惠券?","answer":"在結帳頁面輸入優惠碼,系統會自動折抵。"}
]
df = pd.DataFrame(data)
df.to_csv("faqs.csv", index=False, encoding="utf-8-sig")
print("FAQs count:", len(df))
EMB_PATH = "faq_question_embeddings.npy"
MODEL_NAME = "sentence-transformers/paraphrase-multilingual-MiniLM-L12-v2"
embedder = SentenceTransformer(MODEL_NAME)
if os.path.exists(EMB_PATH):
embeddings = np.load(EMB_PATH)
print("Loaded embeddings:", embeddings.shape)
else:
texts = df["question"].astype(str).tolist()
embeddings = embedder.encode(texts, convert_to_numpy=True, show_progress_bar=True).astype("float32")
np.save(EMB_PATH, embeddings)
print("Saved embeddings:", embeddings.shape)
ids = df["id"].astype(str).tolist()
collection = None
if CHROMA_AVAILABLE:
client = PersistentClient(path="./chroma_db")
col_name = "faq_collection"
try:
collection = client.get_collection(col_name)
except Exception:
collection = client.create_collection(name=col_name)
try:
existing_ids = collection.get(include=["ids"])["ids"]
except Exception:
existing_ids = []
if len(existing_ids) == 0:
metadatas = [{"id": row["id"], "question": row["question"], "answer": row["answer"]} for _, row in df.iterrows()]
collection.upsert(ids=ids, documents=df["question"].tolist(), metadatas=metadatas, embeddings=embeddings.tolist())
print("Upserted into Chroma.")
else:
print("Chroma collection exists with", len(existing_ids), "ids.")
faiss_index = None
if FAISS_AVAILABLE:
emb = embeddings.astype("float32")
faiss.normalize_L2(emb) # normalize -> inner product == cosine
d = emb.shape[1]
faiss_index = faiss.IndexFlatIP(d)
faiss_index.add(emb)
print("FAISS index ntotal:", faiss_index.ntotal)
# ===== 5) 檢索 helper(兩個版本:Chroma / Faiss) =====
def retrieve_chroma(query, k=3):
q_emb = embedder.encode([query], convert_to_numpy=True).tolist()
res = collection.query(query_embeddings=q_emb, n_results=k, include=["metadatas","documents","distances"])
docs = []
# Note: distances 的方向/意義可能依 Chroma 版本不同,下面暫當「score 越大越好」
for i in range(len(res["documents"][0])):
meta = res["metadatas"][0][i]
dist = res["distances"][0][i] if res.get("distances") else None
docs.append({"id": meta.get("id"), "question": meta.get("question"), "answer": meta.get("answer"), "score": float(dist) if dist is not None else None})
return docs
def retrieve_faiss(query, k=3):
q_emb = embedder.encode([query], convert_to_numpy=True).astype("float32")
faiss.normalize_L2(q_emb)
D, I = faiss_index.search(q_emb, k)
out = []
for score, idx in zip(D[0], I[0]):
idx = int(idx)
out.append({"id": ids[idx], "question": df.iloc[idx]["question"], "answer": df.iloc[idx]["answer"], "score": float(score)})
return out
eval_samples = [
{"query":"我要退貨要怎麼做?", "gold":"q1"},
{"query":"運費怎麼算?", "gold":"q2"},
{"query":"可以更改收件地址嗎?", "gold":"q3"},
{"query":"可以用貨到付款嗎?", "gold":"q4"},
{"query":"商品多久送到?", "gold":"q5"},
{"query":"我怎麼查訂單?", "gold":"q6"},
{"query":"發票會寄到哪裡?", "gold":"q7"},
{"query":"產品壞掉我能換貨嗎?", "gold":"q8"},
{"query":"客服電話是多少?", "gold":"q9"},
{"query":"我有優惠券怎麼用?", "gold":"q10"}
]
eval_df = pd.DataFrame(eval_samples)
print("Evaluation samples:", len(eval_df))
# ===== 7) 先觀察 top1 score 的分布(重要:不同 DB score 意義可能不同) =====
print("\n-- Sample top1 scores (for inspection) --")
top1_scores = []
for row in eval_df.itertuples():
if collection is not None:
r = retrieve_chroma(row.query, k=1)
elif faiss_index is not None:
r = retrieve_faiss(row.query, k=1)
else:
raise RuntimeError("No retriever available")
s = r[0]["score"] if len(r)>0 else None
top1_scores.append(s)
print("top1 scores:", top1_scores)
print("min:", np.nanmin(top1_scores), "max:", np.nanmax(top1_scores), "mean:", np.nanmean(top1_scores))
print("\n**注意**:若上面顯示的分數越大越相似(通常 FAISS 是如此)。若 Chroma 回傳的是距離(越小越好),你可以把距離轉成相似度,例如 sim = 1/(1+distance)。")
k_list = [1, 3, 5]
threshold_list = [None, 0.2, 0.3, 0.4, 0.5] # None 表示不做閾值 abstain
# 建議:若 FAISS(normalized IP) 則 threshold 介於 0.2~0.6 合理;若 Chroma distances 是「距離」,請先轉換再比較。
# ===== 9) 定義判定邏輯(top1 比對 gold or top-k 包含 gold) =====
def evaluate(retriever_name="chroma", k_vals=[1,3,5], thresholds=[None]):
rows = []
for k in k_vals:
for thr in thresholds:
correct = 0
total = len(eval_df)
abstain_count = 0
for rrow in eval_df.itertuples():
query = rrow.query
gold = rrow.gold
if retriever_name == "chroma":
hits = retrieve_chroma(query, k=k)
else:
hits = retrieve_faiss(query, k=k)
# if no hits
if not hits:
predicted = None
top_score = None
else:
top_score = hits[0]["score"]
# 如果使用閾值 (thr not None) 且 top_score 是數值,則可能做 abstain
if thr is not None and top_score is not None:
# **假設** score 越大越好(FAISS),對於 Chroma 若為距離/越小越好請自行轉換
if top_score < thr:
abstain_count += 1
predicted = None
else:
# 評估方式:判斷 top-1 是否為 gold
predicted = hits[0]["id"]
else:
predicted = hits[0]["id"]
# 判斷 correct(top1 exact match)
is_correct = (predicted == gold)
if is_correct:
correct += 1
rows.append({"k":k, "threshold":thr, "query":query, "gold":gold, "predicted":predicted, "top_score":top_score, "is_correct":is_correct})
# summary
accuracy = correct / total
coverage = (total - abstain_count) / total
print(f"k={k}, thr={thr}, accuracy={accuracy:.3f}, coverage={coverage:.3f} (abstain {abstain_count}/{total})")
return pd.DataFrame(rows)
# ===== 10) 執行評估並得到比較表 =====
results_df = evaluate(retriever_name=("chroma" if collection is not None else "faiss"), k_vals=k_list, thresholds=threshold_list)
# ===== 11) 產生 k vs accuracy 的 summary table(top1 exact-match) =====
summary = results_df.groupby(["k","threshold"]).agg(
accuracy=("is_correct", "mean"),
count=("is_correct", "count")
).reset_index()
print("\n=== Summary table ===")
display(summary)
out_csv = "retrieval_eval_for_manual.csv"
# 先縮減只保留 k,threshold,query,gold,predicted,top_score
results_df[["k","threshold","query","gold","predicted","top_score","is_correct"]].to_csv(out_csv, index=False, encoding="utf-8-sig")
print("已匯出", out_csv, "(可下載做主觀評分)")
print("\n--- 若你之後手動打分並上傳 CSV(同欄位加 manual_score)可用以下程式匯入計算 ---")
print('''# ex:
# df_manual = pd.read_csv("retrieval_eval_for_manual_scored.csv")
# df_manual['manual_score'] # 0=錯誤, 1=部分, 2=正確
# df_manual['manual_binary'] = df_manual['manual_score'].apply(lambda x: 1 if x==2 else (0.5 if x==1 else 0))
# grouped = df_manual.groupby(["k","threshold"]).manual_binary.mean().reset_index()
# print(grouped)
''')
結果 :
FAQs count: 10
Loaded embeddings: (10, 384)
Upserted into Chroma.
FAISS index ntotal: 10
Evaluation samples: 10
-- Sample top1 scores (for inspection) --
top1 scores: [4.413617134094238, 2.0865445137023926, 2.0459953176121815e-12, 6.451347827911377, 2.0488173961639404, 4.869661808013916, 6.015843868255615, 11.014286994934082, 9.192691802978516, 1.8463075160980225]
min: 2.0459953176121815e-12 max: 11.014286994934082 mean: 4.793911886215414
注意:若上面顯示的分數越大越相似(通常 FAISS 是如此)。若 Chroma 回傳的是距離(越小越好),你可以把距離轉成相似度,例如 sim = 1/(1+distance)。
k=1, thr=None, accuracy=1.000, coverage=1.000 (abstain 0/10)
k=1, thr=0.2, accuracy=0.900, coverage=0.900 (abstain 1/10)
k=1, thr=0.3, accuracy=0.900, coverage=0.900 (abstain 1/10)
k=1, thr=0.4, accuracy=0.900, coverage=0.900 (abstain 1/10)
k=1, thr=0.5, accuracy=0.900, coverage=0.900 (abstain 1/10)
k=3, thr=None, accuracy=1.000, coverage=1.000 (abstain 0/10)
k=3, thr=0.2, accuracy=0.900, coverage=0.900 (abstain 1/10)
k=3, thr=0.3, accuracy=0.900, coverage=0.900 (abstain 1/10)
k=3, thr=0.4, accuracy=0.900, coverage=0.900 (abstain 1/10)
k=3, thr=0.5, accuracy=0.900, coverage=0.900 (abstain 1/10)
k=5, thr=None, accuracy=1.000, coverage=1.000 (abstain 0/10)
k=5, thr=0.2, accuracy=0.900, coverage=0.900 (abstain 1/10)
k=5, thr=0.3, accuracy=0.900, coverage=0.900 (abstain 1/10)
k=5, thr=0.4, accuracy=0.900, coverage=0.900 (abstain 1/10)
k=5, thr=0.5, accuracy=0.900, coverage=0.900 (abstain 1/10)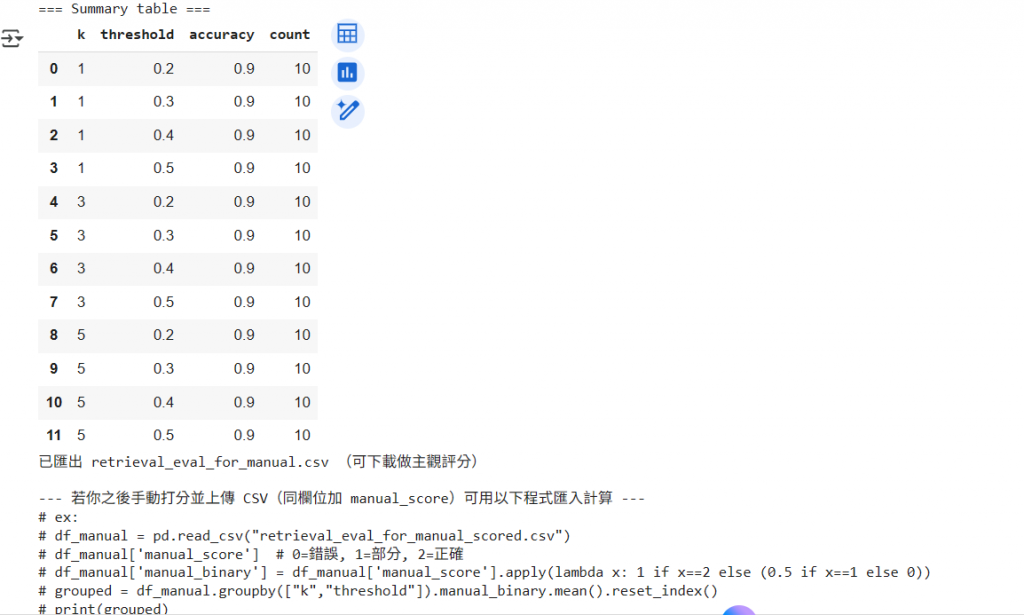


 iThome鐵人賽
iThome鐵人賽